
Designing neuro-inclusive incident management
Incident response processes can disproportionately disadvantage neurodivergent engineers. This is a write-up from my talk at the LDX3 London 2026 conference by LeadDev about how small, intentional changes to incident management can reduce cognitive load, support neurodivergent engineers, and improve reliability for everyone.
This write-up includes parts that have been cut from the final talk version.

Higher AI adoption is associated with higher levels of software delivery instability.
Source: State of AI-assisted Software Development 2025 report by DORA

Let's do the "Hi!" activity. I'd like you to say, "hi!" to two people, one on your right and one on your left.

The "Hi!" activity is based on the stats that 53% of people in tech identify themselves as neurodivergent. So 1 of the 2 people you just said, "hi" to might identify themself as neurodivergent.
Source: Diversity in Tech 2024 report by Tech Talent Charter
So with a lot of people identifying themselves as neurodivergent and the fact that software incidents are increasing, isn’t it about time to make it easier for neurodivergent people to manage incidents?
Before we dive deeper, I’d like to share that each neurodivergent person has their own unique experiences of the world. So some of what I’m going to say may feel very true for some of us while some may not resonate with it too much.
Story (~7 minute long)

Let's start with a story.
You'll be on call from this afternoon, and you still haven't finished reading all the runbooks. Forty pages of passive reading, with no urgency. Without urgency, your brain goes elsewhere.
Then the on-call shift starts.
You check the dashboards. Fine. You check Slack. Nothing urgent.
At night, you can’t sleep. Intrusive thoughts keep circling. But eventually, exhaustion wins.
Phone face-down. Brain deep asleep. Then the page hits. Your phone is ringing the tune when an incident is detected.
Your body wakes before your mind. Heart racing. Breath shallow. By the time you reach your phone, you're fully, violently awake.
It’s not just a sound. It’s more like a police siren. But you’re not in your bedroom hearing the siren. It feels more like, you’re lying on top of the police car, facing the siren. It’s unbearably loud. Unbearably bright. Even with the lowest volume and brightness setting on your phone.
It just has to stop ringing, so that you can be you again. So that you can think again.
You acknowledge the page. Open your laptop.
And then it arrives. That shift. Those tingles.
Real stakes. Something is actually broken. This is exciting!
Your attention locks in. You’re completely present. You’re pulling metrics, building timelines, scanning logs with a level of focus you can’t summon on demand, but which shows up reliably when it matters.
You are the incident commander.
Which means you’re expected to be present in Slack. Responsive, visible. But every time you surface to answer, you lose depth. And depth is where you work.
You’re switching constantly: investigation, communication, investigation, communication. Back and forth.
Then you noticed your manager sends a direct message: a director is waiting on severity.
You say you don’t know yet.
Your manager replies: “You have to respond. You don’t have to answer, just respond.”
You pause. Confused. Then type: “Still investigating. Impact unknown.”
And you thought, this answer really doesn’t matter, it’s not even answering the question. But at least your manager is off your back now…
Back to the data. You notice something. Not the spike everyone is watching, but a small dip just before it. You follow it.
But suddenly, a live call starts. You’re expected to join. Cameras on. At 2 in the morning! 😭
Updates every few minutes. Spoken out loud, while the work is still happening. You try to split your attention.
But the state you were in, that precise & generative focus, doesn’t fully return.
Despite that, you finally see it. The root cause is clear to you. The impact makes sense.
You send the severity: sev-3.
But then just when you’re about to share the root cause, you cannot remember it! Where did it go?
Wait, what’s the last thing that you can remember? Oh, yeah, it’s the director’s face in the call when you told them the incident had a low impact. You don’t know what’s going on behind that facial expression, but you just can’t stop replaying it for some reason 🤔
On the call, your manager restarts a few services. The errors drop and stabilise.
The incident closes. Not with your theory, which you forgot before you shared it.
Later, alone, the root cause comes back to you. You make a small change in the Terraform code to prevent it happening again. It’s only a one line change, so you don’t make a big fuss about it 🤷♀️
In the post-mortem, the discussion is verbal. Fast. Fluid.
You have more to say, but you can’t find the moment to enter.
Then, the feedback comes: "You weren’t communicative enough. A director spent time on something low impact."
It’s framed as professional conduct. But you hear it as something else entirely.
“You should have known what they needed without being told. You should have read the room. In your role, you should be able to navigate ambiguity and not be told what people actually mean when they say something.”
You think, “I can’t read people’s minds, this is so unfair!” 😡
So what do you do next? You apologise. You apologise the way you've learned to apologise when the social rules were never explained to you. You apologise even when deep inside, you know you can never naturally read the implicit social rules.
But the pattern you spotted that night? The correct root cause you found, alone, at 2am, under conditions that would have made many engineers guess and escalate? The one you quietly fixed without the fanfare?
None of it made it into the post-mortem doc.

Well, that’s a bit dark, wasn’t it? A lot of things gone wrong in that story, and many of them are preventable. However, many good things happened, too. Let’s look at them…
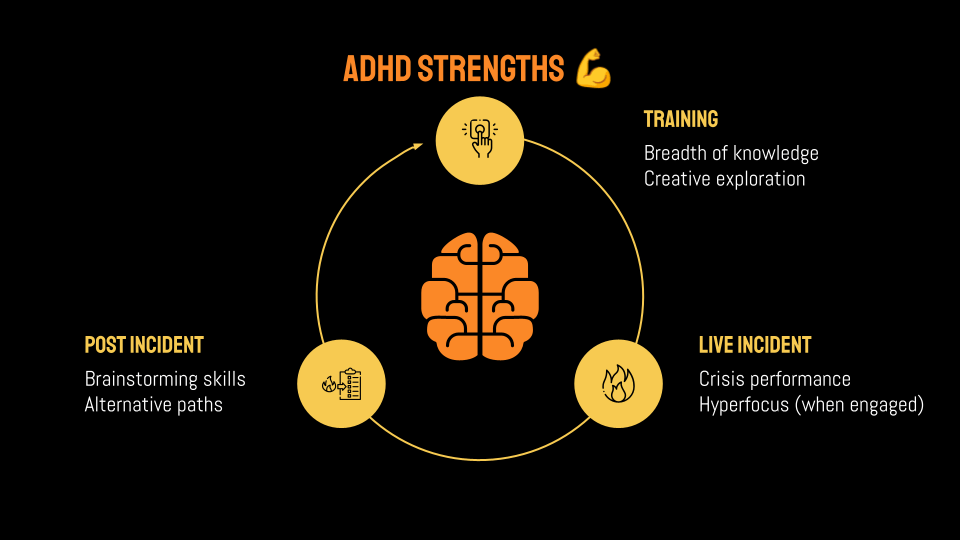
Let's start with ADHD strengths.
In training, given the right environment, ADHD engineers tend to build broad system awareness. Their non-linear approach can lead to creative explorations.
In live incident, this is where ADHD strengths often peak.
Urgency and pressure trigger a performance uplift: increasing focus, speed, and engagement.
When engaged, hyper-focus allows them to dive deeply into a problem.
Post incident, they contribute big-picture thinking identifying alternative approaches, missed opportunities, and different ways the incident could have been handled.
Overall, ADHD engineers can drive fast, creative, and high-impact problem solvings.
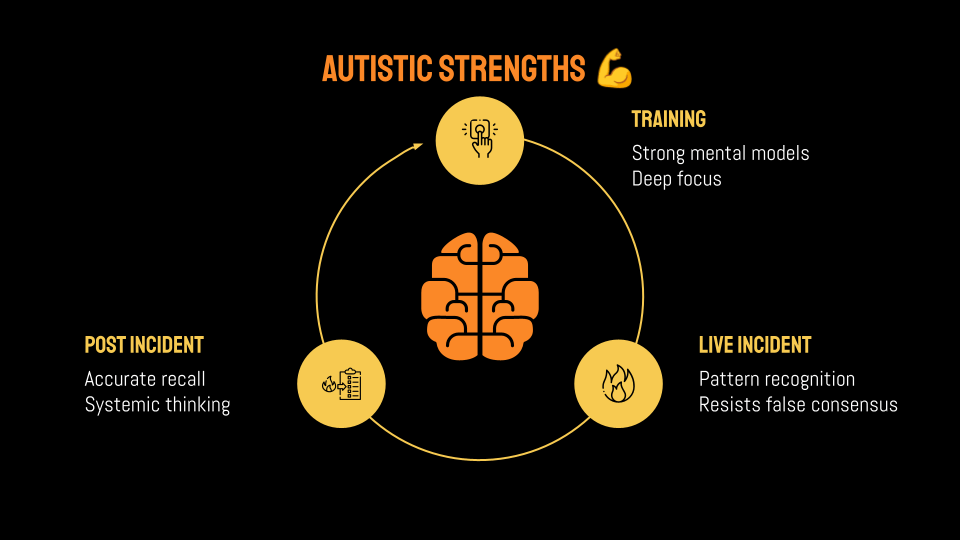
Autistic people can be highly capable, but also highly sensitive to threats and ambiguity.
In training, in the right environment, autistic engineers build exceptionally strong mental models of systems and can sustain deep focus far beyond typical learning patterns.
In live incident, they excel at deep debugging, noticing small but critical details others might miss, and importantly, resisting false consensus.
Post incident, they can have highly accurate recall and the ability to generate unconventional insights based on systemic thinking.
Overall, autistic engineers can bring understanding of complex systems and deeply impactful problem solving.
For these strengths to show up, they need specific environments. What are the environments that these neurotypes need?
There are other neurotypes with their own different needs. However, for this talk, I’m going to focus on autism and ADHD, or a mix of both, also called AuDHD.
Incident Training

Let’s start with training.
Based on my own interviews with a few neurodivergent engineers, they are especially anxious about running their first incidents. Interestingly, although they have run incidents before, for example in their previous jobs or previous teams, some of them still have high anxiety about their first incidents in their current team/job.
The most important thing for trainings is that both ADHD and autistic engineers learn better by doing compared to by reading, but for different reasons. Autistic engineers benefit from embodied procedural memory, a.k.a. muscle memory. ADHD engineers benefit because action creates the interest and immediacy.

So how do we make trainings more neuro-inclusive?
The answer is not throwing long onboarding documents. But instead, creating hands-on trainings with increasing stakes and risks.
Start with safe exercises to get familiar with the incident management process:
Declare an incident
Triage the severity
Run the incident
Escalate
Pause the incident
Do a handover
Close the incident
Do a post-mortem/debrief
Exercises can be anything that’s not live incidents, it can be game days or simulated incidents. Or it can also be a walkthrough of previous incidents.
It can also be scenarios that needs lower setup, such as the lunch incident exercise from Slack.
The next step is shadow on-calls where people can get involved in live incidents, but still in a safe way.
Starting with being an observer/passive contributor then gradually becoming active contributor, a.k.a. active/reversed shadow on-call.
Remember, incident trainings are not only for juniors! Seniors, staff engineers, principals, managers, whoever involved in incident management can benefit from trainings. They could be new team members, someone back from a long leave, or perhaps a new incident process is just introduced in your organisation.
Live Incident

How can we make live incident management more neuro-inclusive?
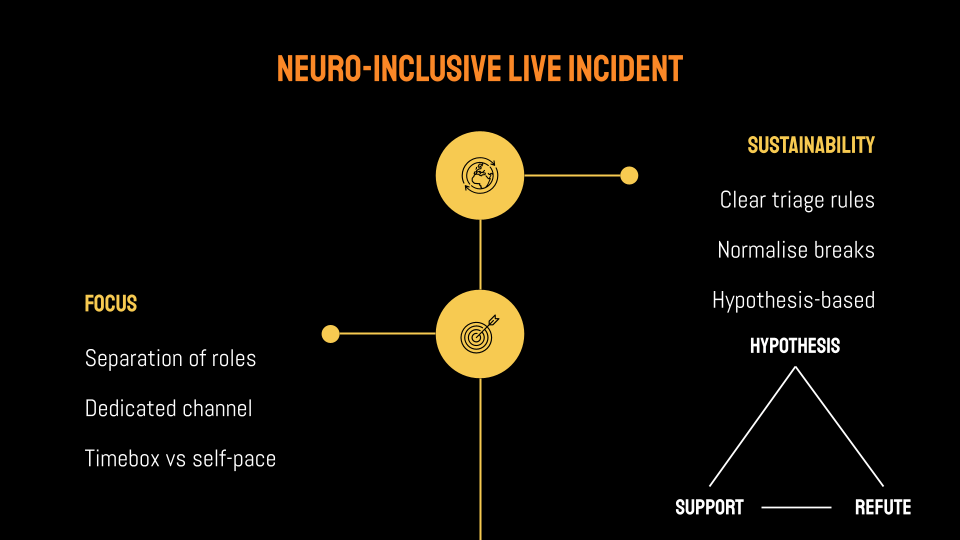
Focus
Separation of roles
Just like in software design, we can use the Single Responsibility Principle by separating the roles of incident investigators (those who investigate/debug deeply, test hypotheses, and restore the systems) and the incident communicators (those who regularly summarise the state of the live incident and communicate to relevant stakeholders).
If your organisation doesn't have the capacity to have one person as an investigator and another person as a communicator for each live incidents, you may want to look into automation.
Where to invest the incident automation?
It depends! If your organisation values resolving incidents quickly over building relationships with customers then automate the communicator role, e.g. by automating the health status page.
Otherwise, you may want to automate the investigator role, e.g. by using AI SRE (at the time or writing, AI SRE is still on the early days and humans are still needed in this role).
In highly regulated sectors you may already have a dedicated incident communicator role who reports to the regulatory bodies for major incidents.
Dedicated channel
Use a dedicated channel, for example one Slack/Discord/Microsoft Teams channel or one Google Chat space. Some organisations have a dedicated channel per incident while some have a dedicated channel for all incidents, it depends on the frequency and the complexity of the incidents in your organisations.
Avoid discussions in back-channels because it can lead to miscommunications or missing information or the toil of copying over the important chat in the wider channel.
However, back channels useful for for private matters such as medical conditions, family urgency, checking or confirming emotional escalations with a trusted person/manager, etc.
Timebox vs self-pace
Timebox helps with focus for people who might go down the rabbit holes or unaware of the passing times. It can look for example like this:
“We're at T+20, let's see if we can isolate the root cause before T+40.”
As a caveat: timebox can be perceived as unnecessary pressure for some people. For some people who are highly sensitive to pressure, a self-paced process reduces the intensity of stress and therefore free up their energy to do their job.
Sustainability
Clear triage rules
With clear triage rules, the severity level of an incident is assigned based on pre-defined rules, not by who screams the most or by how stressed the engineer or the leadership is that day.
For example, a major incidents could be:
An x number of customers affected (make sure the x is defined somewhere!)
A critical business feature (make sure the list of critical business features are defined somewhere!)
One of the major customers/partners affected (make sure the major customers/partners are listed somewhere!)
Make it clearly defined and written.
Normalise breaks
Breaks are helpful for long running incident where people with interoception struggles may not realise they haven’t taken toilet breaks or missed their regular meals or sleep deprived, etc.
Don’t assume people will stop when they’re tired or need bio breaks. Normalise breaks by explicitly saying things like:
“I’m taking 0.5hr break and will be back after dinner”
“Let’s pause the incident until we get more external feedback”
Hypothesis-based
Borrowing from the science & research processes, where problems are solved starting from creating hypotheses.
When a hypothesis is created, we gather the evidence to support as well as the evidence to refute the hypothesis. The emphasis here is that the evidence are gathered against the hypothesis, not the person who suggested the hypothesis. This is helpful for preventing triggering Rejection Sensitivity Dysphoria, which can feel very disabling.
It would be useful to include the hypothesis-based process in the incident training.
Time relativity around incident

Time relativity is the phenomenon where time passes at different rates for different roles.
Incident investigators may not be aware of time. While non-investigator roles (observers, communicators) may feel anxious while waiting for the system to restore.
If you are not an investigator, please remember that sometimes no news means good news. It is hard to get out of the way so other people can focus, but …
Forcing people to regularly give you update breaks their focus. It may make you feel less anxious, but it more stressful for the investigator.
Forcing people to pair or go on a live call so you can feel that things are progressing also makes more stressful for the investigator.
However, regular check-ins & body-doubling can be useful, too! Especially for some ADHD people who need accountability and timebox structure.
But how do you tell who needs what?
It's about choice, because there's no one size that fits all.
You can ask:
Do you prefer regular check-ins/timebox or self-pace?
Do you prefer a live call or async right now?
Clear and precise language
Rather than asking "How can I help?" when you're implicitly asking "How long do you think it takes to restore the system?", just ask:
"How long do you think it takes to restore the system?"
Clarity wins over the awkwardness of being direct.
You can use the neuroinclusive guide and checklist by Georgia Broome, originally developed for the Department of Computer Science at the University of Oxford.
Post incident

How can we make post incident more neuro-inclusive?

For the post mortem (a.k.a. debrief):
Do not give a blank document to the incident commander/lead because it can trigger writer’s block and induce inertia. Automate the 1st draft as much as possible and let humans edit the draft afterwards.
Do not just rely on verbal-only “five whys” session without any documents because it can trigger masking and overwhelm. Go async-first so people can reflect and analyse the incident in their own space and time before the meeting.
Protect focus and deep thinking, social battery
Prevent performative work and masking, peer pressure
Do have action items but make sure they have deadlines and/or “Done” criteria so they don't triggers inertia.
Specific
Measurable
Achievable
Relevant
Time-bound
The foundation of it all is blameless culture to hold the psychological safety. If you have human errors as the root cause for any of your incidents, it's a big red flag that psychological safety might not be there yet.
Recovery for humans

Next time you meet someone who have recently been in an incident, ask about their wellbeing. However, if they don't answer when you ask:
"How are you?" And they answer about the weather, they may be thinking that you’re only initiating a small talk.
"How are you feeling about the incident?" And they answer with facts instead of their feelings, because they may have Alexithymia and therefore unable to describe their feelings or have delayed emotional processing.
You could try asking different questions, such as:
What is your energy level after your last incident?
You can take a day off after managing a sev-0. When are you planning to take it?
How are you planning to rest & recover from your last incident?
Neurodivergent people are more prone to stress due to the expectations to be more like neurotypical people. If you're worried you or someone you work with might be burn out, you could try the Risk of Burnout Questionnaire by British Medical Association. It was originally created for doctors, but I think it's relevant for the tech industry.
On disclosure
Do you need to do all these? Can't neurodivergent people just ask for accommodations if they need them? Do you have to tweak or change your incident management process/culture right now?
The thing is, not many neurodivergent people disclose their neurotype!
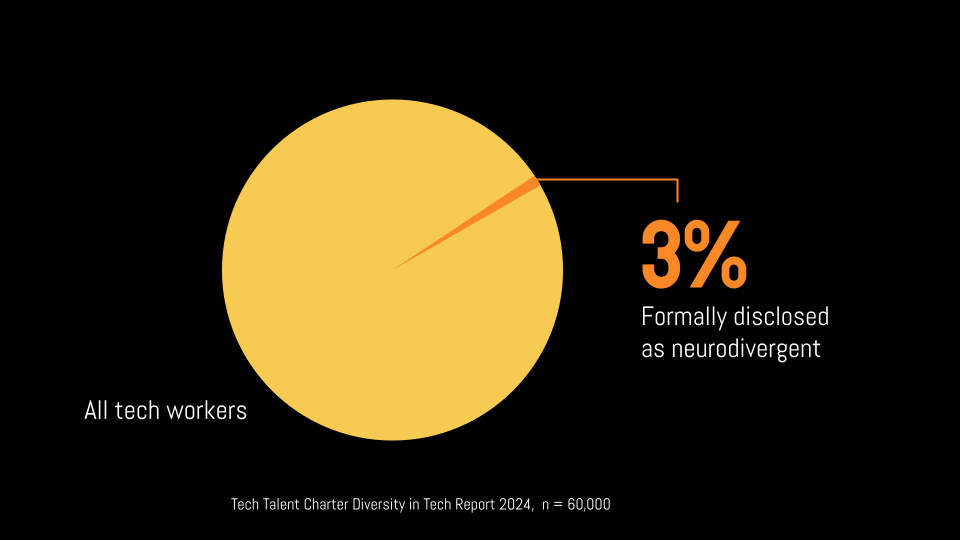
Statistically, there are only 3% out of all tech workers disclose themselves as neurodivergent.
Remember the “Hi 👋” activity? With 53% people may by identifying themselves as neurodivergent?
Such a striking difference!
But why would people not disclose their neurodivergence?
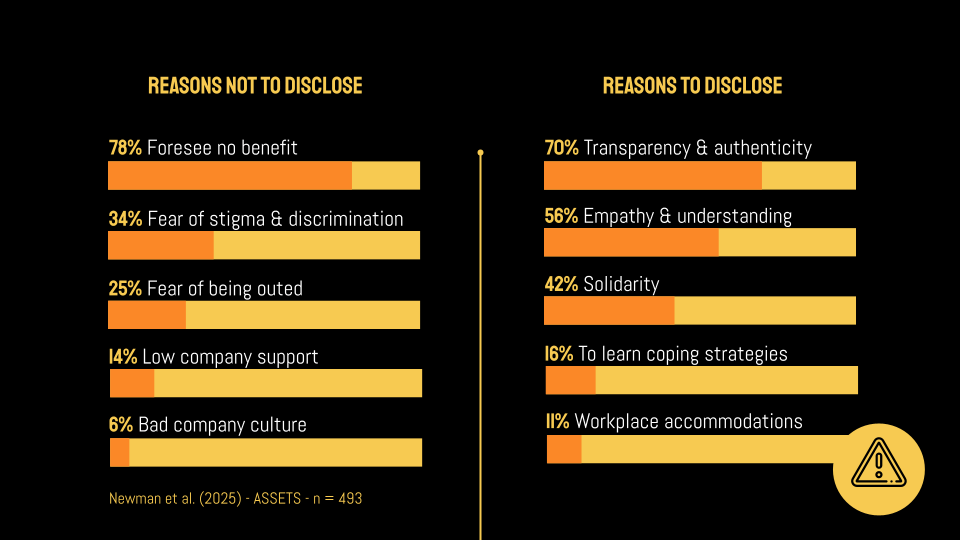
There are many reasons for people not to disclose, with top reasons being:
Foresee no benefit
Fear of stigma & discrimination
However, when people do disclose, the top reasons are:
Transparency & authenticity
Empathy & understanding
So when the few people do disclose, they mostly want to be who they are, to be accepted as they are.
There are actually only 11% who disclosed actually did that to request for workplace accommodations. So statistically speaking, waiting & relying on neurodivergent people to disclose and ask for accommodations is not very effective!
So what can you do instead?
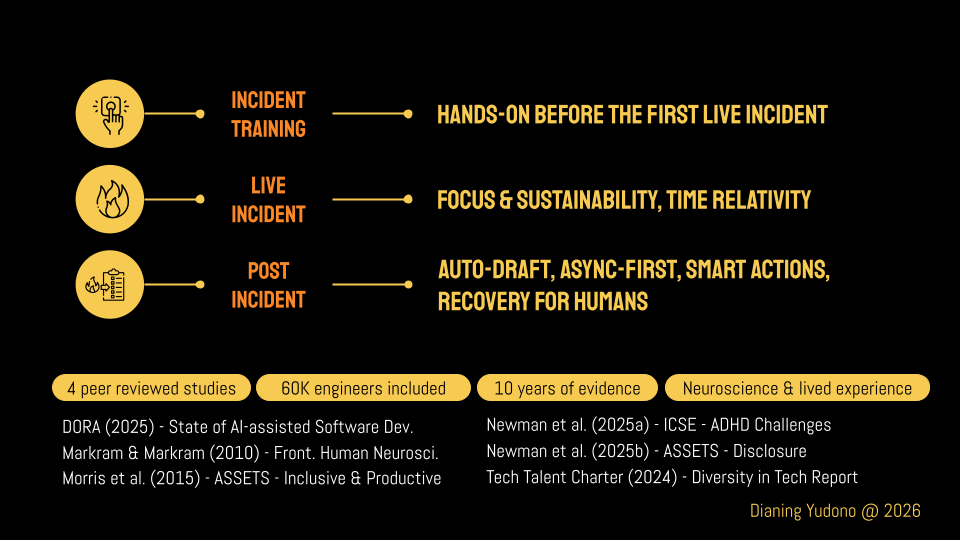
A few things:
Incident training: create hands-on exercises before the first live incident.
Live incident: protect focus & encourage sustainability, and be aware of time relativity and how it affects different roles.
Post incident: auto-draft the post-mortem/debrief report, go async first before the post-mortem/debrief meeting, create SMART actions, and always include the recovery for humans.
Resources
All the wonderful and generous neurodivergent folks whom I interviewed for this talk. I thank you so much 🫶
DORA. 2025. " State of AI-assisted Software Development" https://dora.dev/dora-report-2025/
Markram & Markram. 2010. The Intense World Theory – A Unifying Theory of the Neurobiology of Autism
Morris et al. 2015. Understanding the Challenges Faced by NeurodiverseSoftware Engineering Employees: Towards a MoreInclusive and Productive Technical Workforce
Newman et al. 2025. “Get Me In The Groove”: A Mixed Methods Study on Supporting ADHD Professional Programmers
Newman at al. 2025. Disclosure of Neurodivergence in Software Workplaces: a MixedMethods Study of Forum and Survey Perspectives
Tech Talent Charter. 2024. Diversity in Tech Report
https://www.techtalentcharter.co.uk/reports/diversity-in-tech-report-2024/

Dianing Yudono is a personal growth and career coach for individual contributors in tech.
©2026 Dianing Yudono